Passo a passo de como fazer uma análise de Churn — Parte 1
Provavelmente um das maiorias dores de cabeça de uma organização. se pudermos entender o porque os clientes deixam de comprar com uma certa acurácia, nós podemos imediatamente criar estratégias e iniciativas para reter esses clientes. Nesse artigo pretendo fazer com que entenda como aplicar um modelo preditivo de churn em Python. Para isso, iremos utilizar o aprendizado supervisionado para tentar resolver alguns desafios de negocio.

O artigo será dividido em quatro partes que irão nos guiar para concluir um modelo preditivo de churn com sucesso. Para reproduzir o estudo disponibilizei os dataset.
Parte 1: Pré processamento de dados.
Parte 2: Avaliação de dados e seleção do modelo.
Parte 3: Avaliação e melhoria do modelo.
Parte 4: Implementação do modelo.
ATENÇÃO: Se você é ansioso igual a mim, talvez valha pular direto a parte 2, onde as coisas começam a ficar mais interessante, porém, não posso deixar de enfatizar a importância do Pré processamento de dados para esses tipos de problemas, li em algum lugar a seguinte frase que lembro sempre antes de começar meus estudos - “Your model is only as good as your data”.
Tendo isso em vista, bora pro código:
Parte 1 — Pré Processamento de dados
Step 2 — Importando e avaliando a estrutura do dataset:
Step 3 — Avaliação da estrutura de dados:

Aqui, podemos visualizar que os dados são sobre uma base de assinaturas de clientes de uma empresa de telecomunicações, que contém alguns campos como, posse, frequência de pagamento, status atual (se é um cliente ativo ou inativo) e outros dados cadastrais e transacionais. Além disso, aplicando o método describe() vemos que os clientes ficam em média 32 meses e pagam $64 por mês.
Step 4— Analisando a distribuição do campo ‘Churn’

Como podemos ver, o conjunto está desequilibrado com uma alta proporção de clientes ativos, vale ficar de olho se isso não irá afetar na precisão do nosso modelo.
Step 5 — Limpeza e tratamento
Por mais que não tenhamos valores nulos na base de dados, o código abaixo encontra a média e preenche os valores ausentes de forma programática, ou seja, se houver algum valor nulo nas colunas numéricas, devemos encontrar a média de cada uma e preencher seus valores ausentes.
Parte 2: Avaliação de dados e seleção do modelo.
Step 6 — Para entendermos melhor os padrões de dados (caso tenha) vamos visualizar a distribuição das variáveis independentes.
Análise exploratória de dados:
Vamos tentar resumir algumas das principais descobertas deste EDA: O conjunto de dados não contém nenhum valor de dados ausente ou incorreto.
A correlação positiva mais forte com os recursos de destino é Encargos mensais e Idade, enquanto a correlação negativa é com Parceiro, Dependentes e Posse.
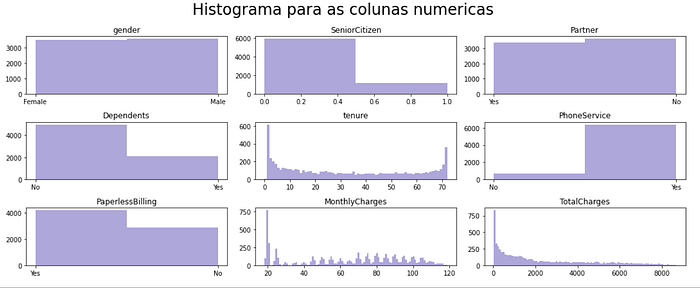
Podemos fazer algumas observações com base nos histogramas acima:
- A distribuição de gênero mostra que o dataset apresenta uma proporção relativamente igual para os gêneros masculino e feminino.
- Quase metade dos clientes tem um parceiros e desses poucos tem dependentes.
- O número de novos clientes é expressivo, com menos de 10 meses na base.
- A maioria dos clientes parece ter serviços de telefone, e desses, 75% optaram, por receber a fatura de forma digital e não impressa (nossa natureza agradeceria se essa taxa ficasse próxima aos 100%)
- As cobranças mensais variam entre $18 a $118, mas existe uma concentração de clientes com valores próximos a $20.
Step 7 — Distribuição do tipo de contrato.
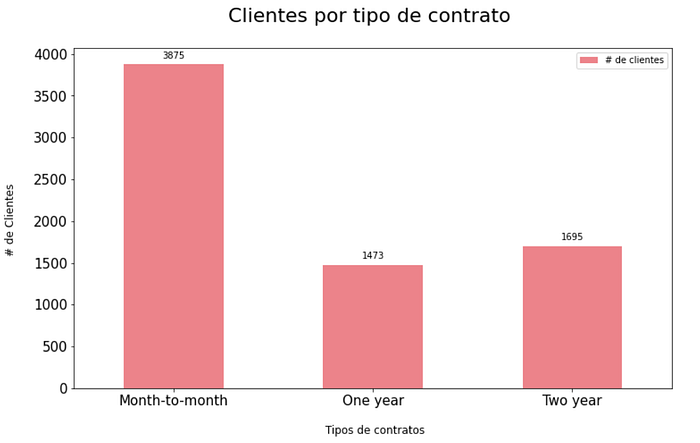
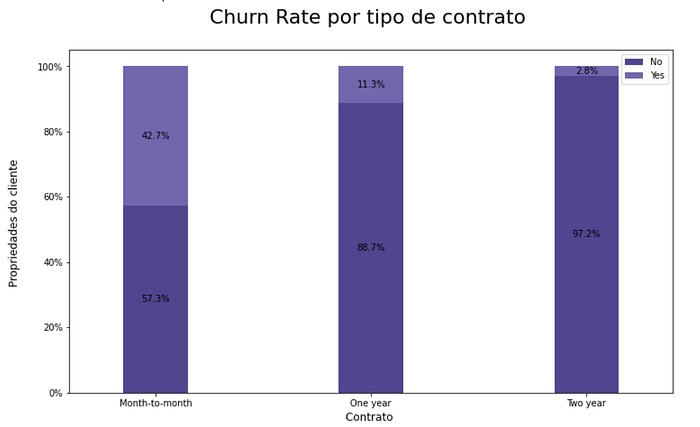
A maioria dos clientes possuem uma conexão com o tipo “Month-to-month” que seria o tipo de contrato pré pago, por outro lado, há uma proporção mais ou menos igual de clientes com contratos de um e dois anos.
Step 8 — Distribuição do método de pagamento.
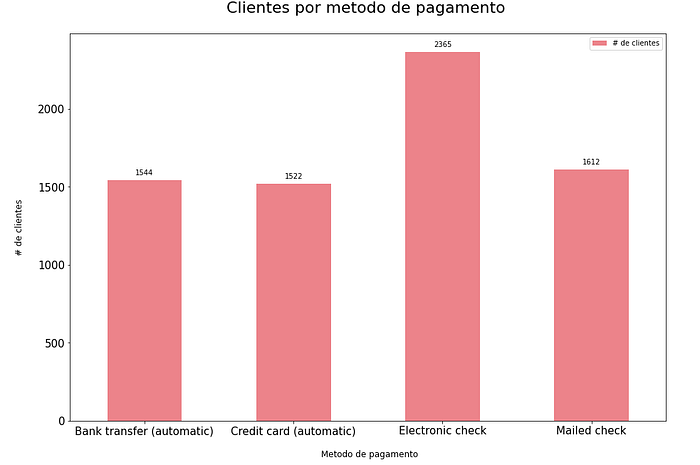
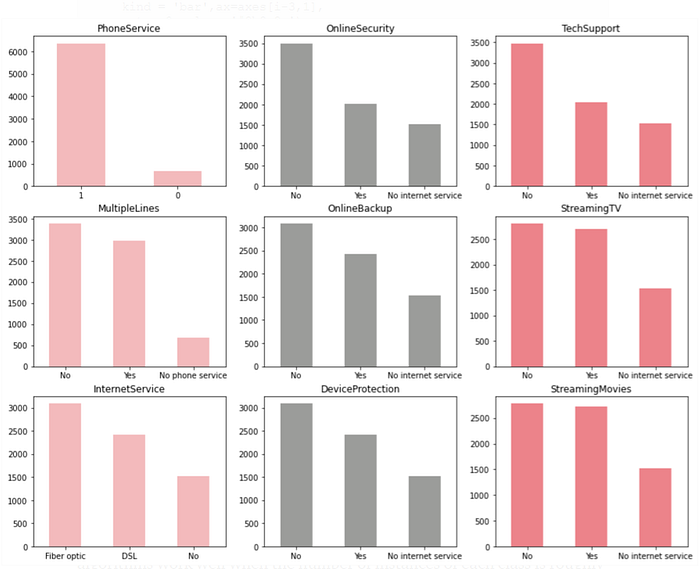
Step 9 — Distribuição das variáveis categóricas.
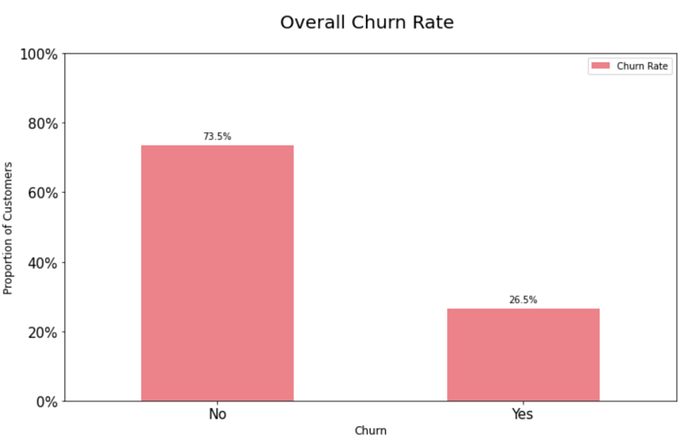
Step 10 — Taxa de churn Geral
Conforme a plotagem abaixo, temos 74% de clientes ativos em nossa base, esse é um problema de classificação descalibrada conforme citado mais a cima. Os algoritmos de Machine Learning funcionam bem quando o número de instancias de cada classe é mais ou menos igual. Como nosso dataset não atende isso temos que nos atentar as métricas lá na frente.
Step 11 — Taxa de churn por tipo de contrato
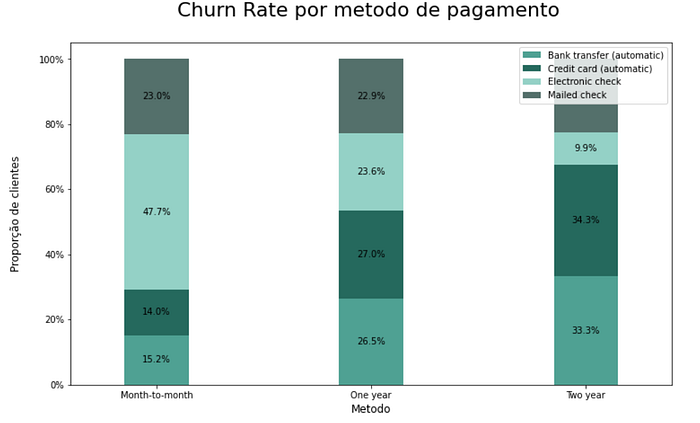
Step 12 — Taxa de churn por tipo de pagamento
Os clientes que pagam por transferência bancária parecem ter a menor taxa de churn entre todos os segmentos de meios de pagamento.
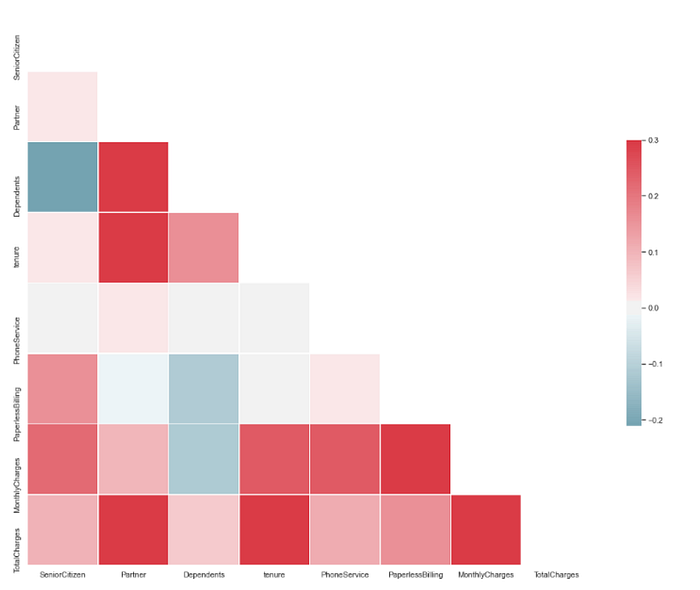
Step 13 — Correlaçoes:
Curiosamente, a taxa de rotatividade aumenta com as taxas mensais e a idade. Em contraste, Parceiro, Dependentes e Posse parecem estar negativamente relacionados à rotatividade. Vamos dar uma olhada nas correlações positivas e negativas graficamente na próxima etapa.
A matriz de correlação nos ajuda a descobrir a relação bivariada entre as variáveis independentes em um conjunto de dados.
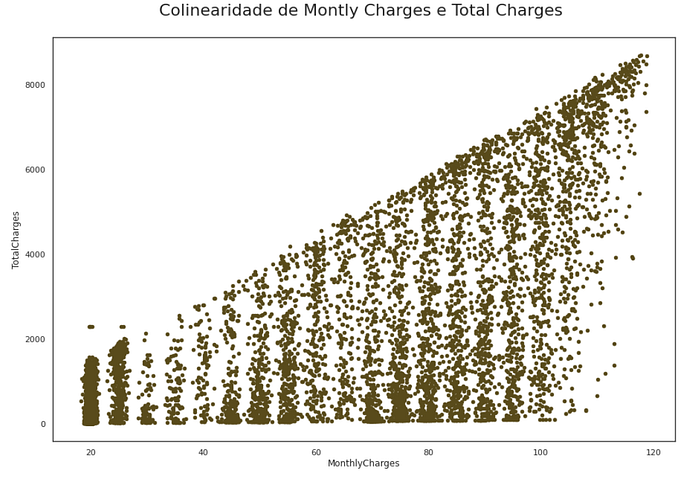
Step 14 — Multicolinearidade
Verifique a multicolinearidade usando VIF: Vamos tentar examinar a multicolinearidade usando Variable Inflation Factors (VIF). Ao contrário da matriz de correlação, o VIF determina a força da correlação de uma variável com um grupo de outras variáveis independentes em um conjunto de dados. VIF começa geralmente em 1 e qualquer lugar que exceda 10 indica alta multicolinearidade entre as variáveis independentes.
O conjunto de dados está desequilibrado com a maioria dos clientes ativos.
Há multicolinearidade entre as cobranças mensais e as cobranças totais. A redução dos encargos totais diminuiu consideravelmente os valores VIF.
A maioria dos clientes no conjunto de dados são jovens.
Existem muitos novos clientes na organização (com menos de 10 meses), seguidos por uma base de clientes leais com mais de 70 meses.
A maioria dos clientes parece ter serviço de telefone com tarifas mensais que variam entre US $ 18 a US $ 118 por cliente.
Os clientes com uma conexão mês a mês têm um
a probabilidade muito alta de abandoná-la também se tiverem assinado o pagamento por meio de cheques eletrônicos.
Parte 3: Avaliação e melhoria do modelo.
Qualquer variável categórica que tenha mais de dois valores únicos foi tratada com Label Encoding e one-hot Encoding usando o método get_dummies em pandas aqui.
Step15 — Divida o conjunto de dados em variáveis dependentes e independentes
Agora precisamos separar o conjunto de dados em valores X e y. y seria a coluna ‘Churn’ enquanto X seria a lista restante de variáveis independentes no conjunto de dados.
Step16 — Realizar o escalonamento de recursos:
É muito importante normalizar as variáveis antes de conduzir qualquer algoritmo de aprendizado de máquina (classificação) para que todas as variáveis de treinamento e teste sejam escaladas dentro de um intervalo de 0 a 1.
Parte 4: Implementação do modelo.
Compare os algoritmos de classificação da linha de base (1ª iteração): vamos modelar cada algoritmo de classificação sobre o conjunto de dados de treinamento e avaliar sua precisão e pontuações de desvio padrão.
A precisão da classificação é uma das métricas de avaliação de classificação mais comuns para comparar algoritmos de linha de base, pois é o número de previsões corretas feitas como uma proporção das previsões totais. No entanto, não é a métrica ideal quando temos problema de desequilíbrio de classe. Portanto, vamos classificar os resultados com base no valor “AUC média”, que nada mais é do que a capacidade do modelo de discriminar entre as classes positivas e negativas.
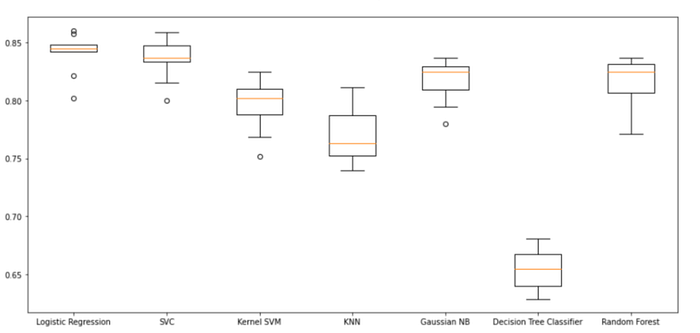
Visualize comparações de precisão de algoritmos de classificação

Usando a área sob a curva ROC: a partir da primeira iteração dos algoritmos de classificação de linha de base, podemos ver que a regressão logística e o SVC superaram os outros cinco modelos para o conjunto de dados escolhido com as maiores pontuações médias de AUC. Vamos reconfirmar nossos resultados na segunda iteração, conforme mostrado nas próximas etapas.
Step 19 — Obtenha os parâmetros corretos para os modelos de linha de base
Antes de fazer a segunda iteração, vamos otimizar os parâmetros e finalizar as métricas de avaliação para a seleção do modelo.
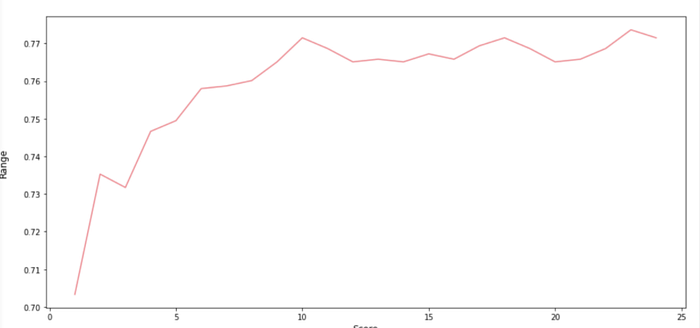
Identifique o número ideal de K vizinhos para o modelo KNN: Na primeira iteração, presumimos que K = 3, mas, na realidade, não sabemos qual é o valor K ideal que dá precisão máxima para o conjunto de dados de treinamento escolhido. Portanto, vamos escrever um loop for que itera de 20 a 30 vezes e forneça a precisão em cada iteração, de modo a descobrir o número ótimo de K vizinhos para o modelo KNN.
Como podemos ver nas iterações acima, se usarmos K = 22, obteremos a pontuação máxima de 78%. Identifique o número ótimo de árvores para o modelo de floresta aleatória: Muito semelhante às iterações no modelo KNN, aqui estamos tentando encontrar o número ótimo de árvores de decisão para compor a melhor floresta aleatória.
Continua…..